As part of a larger trend in modern technofascism, a rising star of what we'll call "alt-tech media" recently made a spectacle of herself by being exposed as wrong, having her identity leaked by the community she betrayed and turned into a national news story. To top it off, she then told a lie in which she claims her laptop got set on fire. I'm talking about DataRepublican (aka "Jennica Pounds"), a former professional software engineer turned performance actor.
I'd like to examine the events in question, along with the claims made. Then, I'll demonstrate how you could trivially examine the same data source she used to make the claim without lighting your computer on fire. With that data available, we'll draw some conclusions about if DataRepublican was mistaken, incompetent, or lying. We'll demonstrate this via both the technical dive into the data, followed by an examination of who DataRepublican claims to be, in her own words.
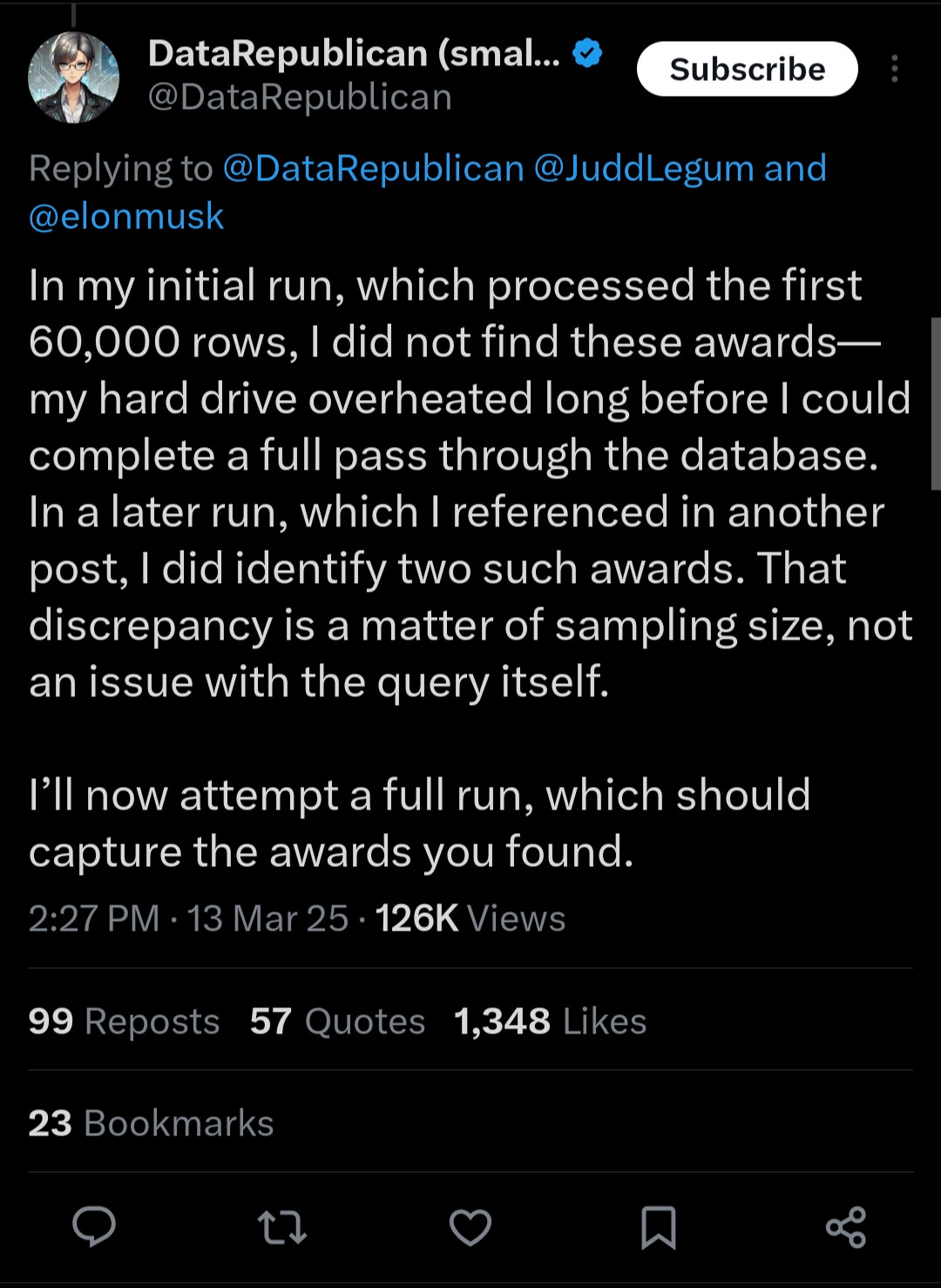
But, we should start at the beginning. DataRepublican was pressed about details of a conversation with another DOGE-cheerleadingThe Department of Government Efficiency, Elon Musk's pet project.Twitter user.
Molly White appeared on scene,
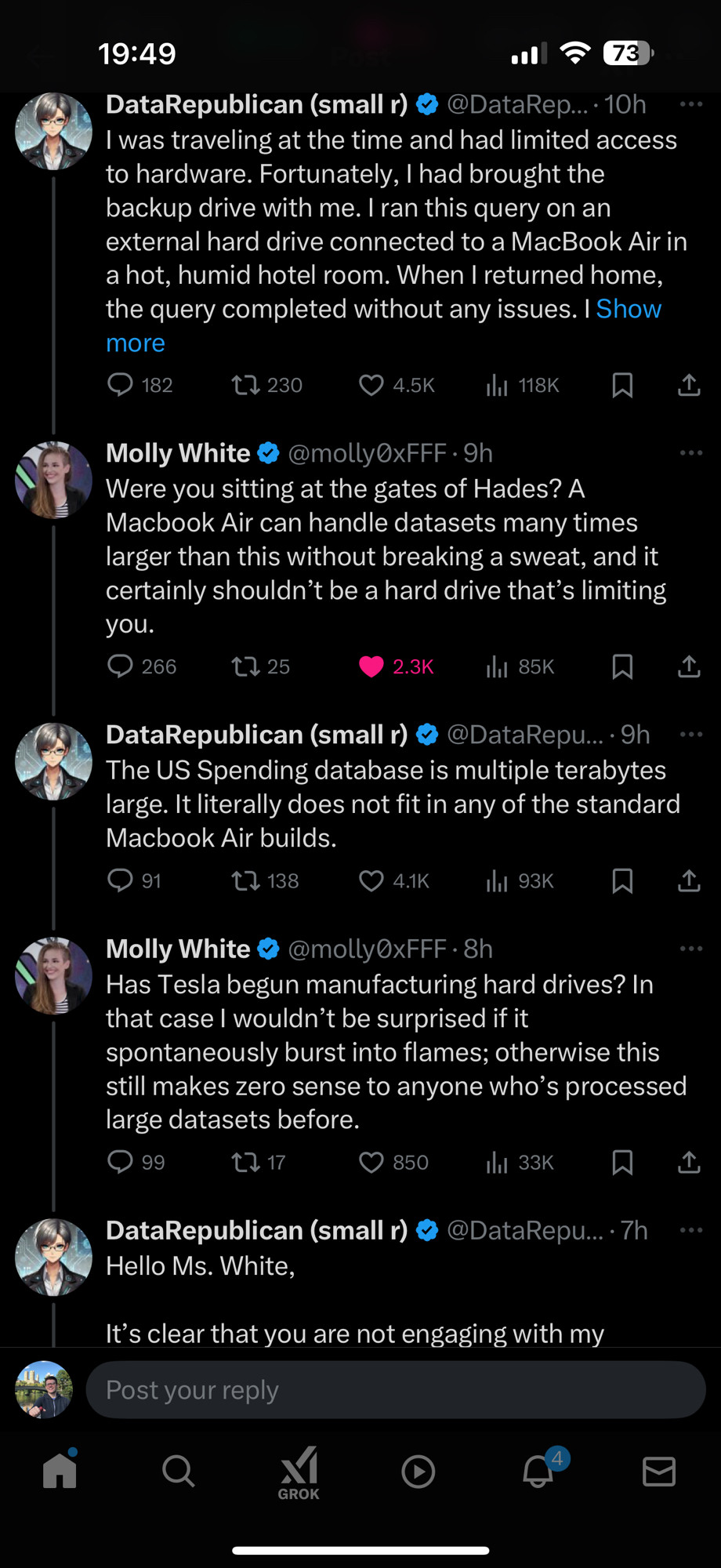
Strange story! For more information on what she was trying to prove about the data, please see "Claim 2" below.
Let's start by breaking this down:
These claims were so outrageous, I was intrigued. I decided to check Jennica's work. After less than an hour of experimentation, I had replicated the entire analysis. For fun, I then did the same analysis on a 2023 Raspberry Pi 5 with 8gb of RAM using an old USB2 hard drive, and even this was a straightforward exercise.
DataRepublican (probably) does not have access to any special data here. She has named her data source as the public website more than once. It turns out you can just go download the contract award data. You can even download this data in other formats. The Award data is distinct from the full spending data which comes as a pre-packaged PostgreSQL database.
The full download of the Award Data (which we will see below is likely what she was referencing) is about 2.1GB zip compressed. This decompresses into just under 9GB worth of CSV. The whole spending data, as a zip archive, is a hefty 145GB download. However, as a PostgreSQL database it wouldn't be held in memory and a half a terabyte isn't that much for a modern disk. What's more, we have some evidence that DR's "60000 row sampling" is an artifact of using an older version of Mac Excel (backed up by her frequent screenshots of an old version).
So it's quite likely she was manipulating the awards_search CSV data, since tools to manipulate CSVs tend to be entirely in memory. That's not even 1% of a terabyte. A terabyte, as a reminder, is 1000GB. A tebibyte is about 1100GB. Neither of these data sets clear into 1 terabyte, let alone a value worth pluralizing. They are certainly large and the full dataset might be too large for a very old MacBook Air, but it's not reasonable to assume this would tax even an inexpensive external hard drive.
Claim 1: False
I managed to dig up a screenshot of the precise nature of her claim about the data, so that I could attempt to replicate it. I'll show you her text and then break it down for you.

Firstly, let's note she's specifically referring to the rpt.awards_search table. This is the "Award Data" listed above, of which the total volume is <9GB. This doesn't sound too bad, but I certainly couldn't hold it in memory on a Raspberry Pi. I selected a popular, open source, 5 year old database package geared towards data science called DuckDB alongside my data science language of choice, Julia.
Importing the data into DuckDB with Julia with a minimal RAM footprint is not very hard:
using DuckDB
db = DBInterface.connect(DuckDB.DB, "usaspending2025-3-10.duckdb")
dbfiles = [ ... ]
ex = DBInterface.execute
ex(db, """
CREATE TABLE awards_search AS
SELECT * FROM read_csv_auto('$(dbfiles[1])', types={...})""")
for dbfile in dbfiles[2:end]
ex(db, """
INSERT INTO awards_search
SELECT * FROM read_csv_auto('$dbfile', types={...})""")
end
This took about 2 minutes on my Framework laptop. On the Raspberry Pi 5, it took almost 5 minutes (likely because of I/O). As we will see below, DuckDB is well suited to this task despite having a much slower CSV parser than what we're accustomed to with Polars or Pandas. On both platforms, most queries shown below executed within seconds. The total memory footprint in both platforms stayed below 3GB, and the final file size for the resident DuckDB file was 2.8GB.
Claim 2: False
Well, since I've got the data loaded I suppose I can just run it over the whole dataset? How many contracts are there with a potential total value above $1M?
ex(db, """SELECT COUNT(*) FROM awards_search
WHERE potential_total_value_of_award > 1e6
AND ordering_period_end_date is not NULL
AND ordering_period_end_date < DATE '2025-01-01'""")
# Result: (var"count_star()" = [273980],)
ex(db,"""SELECT COUNT(*) FROM awards_search
WHERE potential_total_value_of_award > 1e6
AND ordering_period_end_date IS NOT NULL
AND ordering_period_end_date < DATE '2025-01-01'
AND total_outlayed_amount_for_overall_award >
potential_total_value_of_award""")
# (var"count_star()" = [3021],)
# Or 1.1% of contracts overspend.
As we shall see below, even this metric is slightly misleading, but even with DataRepublican's own proposal the cost overrun rate for figure contracts is about 1.1%. Since there are fewer than 60000 items in the entire database that meet her stated criterion, we can safely assume her claim is false. This also refutes her hypothesis more generally. Most contracts don't overspend. That shouldn't be too surprising, contracts are actually highly scrutinized and there's incredible pressure on contractors to never go over budget.
Claim 3: False
Hypothesis: False
We know that overspending happens rarely in large contracts, but we could take the analysis slightly further. When we do overspend, by what percent does that tend to happen by? Representing the overspend as a fraction helps us focus on how accurate the estimates are, rather than worrying about specific dollar amounts, so it seems like a good place to start. It's pretty easy to calculate!
results = ex(db,"""SELECT agency_id,
potential_total_value_of_award,
total_outlayed_amount_for_overall_award
FROM awards_search
WHERE potential_total_value_of_award > 1e6
AND ordering_period_end_date is not NULL
AND ordering_period_end_date < Date '2025-01-01'
AND total_outlayed_amount_for_overall_award >
potential_total_value_of_award """)
rdf = DataFrame(results)
rdf.overspend = round.(
((rdf.total_outlayed_amount_for_overall_award ./
rdf.potential_total_value_of_award) .- 1) .* 10,
digits=2)
rdf_p = percentile(rdf.overspend, [50, 75, 99])
# 3-element Vector{Float64}:
# 9.13
# 19.05
# 221.73
That's interesting. We do see one outlier at a >2x overspend, but the majority of the data seems to be less than 20%. It'd be good to visualize this:
p = density(rdf.overspend, title="% Overspend (When Overspending)",
xlabel="Overspend (%)",
ylabel="Density",
label="",
linewidth=2,
fill=true,
alpha=0.5,
color=:teal,
background_color=:transparent,
framestyle=:box)
vline!([median(rdf.overspend)],
label="Median",
linewidth=2.5,
linestyle=:dash,
color=:orange)
show(p)

As we can seeObservant readers might note the graph appears to have density below 0%. This is just an artifact of how Julia draws these graphs to get a smooth density graph. I could correct for this, but it'd muddle the code, so I chose to keep the slightly incorrect default behavior., there are a few outliers on these big projects, but as a general rule spending lands around 20% of where we expect. And all of this is within the 1.1% of government contracts that overspend, the vast majority do not.
Given the strange claims of a burning computer, arbitrarily small data, and a total lack of evidence for the claim you might be inclined to ask, "Is DataRepublican incompetent?" This is, in a way, a charitable reading of the situation, a classic Dunning-KrugerUsed here informally. Formally, Dunning-Kruger is either a statistical anomaly or such a small effect it can't explain the more general phenomenon that went mainstream.
But, if we examine who DataRepublican is, I think that this is unlikely. I think what this story shows is that DataRepublican isn't very good at lying under pressure, and she got too much scrutiny before she could get her story straight.
DataRepublican is a long-time fixture of right wing discourse circles. Her identity was revealed in 2025 in a Rolling Stone Article as "Jennica Pounds," a woman who worked most recently in the software industry for UpstartShady as defined by me, someone who has spent a lot of time and run a successful fintech startup. These lousy loan products are all predicated on identifying falsely subprime loan customers, but since they serve small volumes they're really just data clearing houses for people who need money. They're one step up from a Payday Loan, but that's still street shark territory., one of the many shady outfits trying to disintermediate people from their money in the US fintech space with a predictable backer: Thiel.
She's been part of the Republican Grift-o-sphere for awhile, and more recently caught Elon's favor as a plausible source of false "Facts" about data. There's room for people like DataRepublican to do this because the Right Wing as a class structure reviles logistics and any sort of technology that enables it, so their pool of talent for actually doing these sorts of analysis credibly isn't deep and anyone competent is jealously guarded (and advised to keep their head down lest their peers recognize them as an intellectual).
Her identity was leaked by other members of the deaf engineering community, that view her as a quisling advocating for the destruction of support structures that enable their independence. Her skill set (along with a somewhat tradwife ethos typical of the modern Right Wing woman) means she doesn't really suffer the same way some of her peers would under various DOGE cuts. Up until recently, her pseudonym had deliberately been presenting a male (or non-specific) identity.
Since that reveal, she seems to have gone full-time grifter. She claims that this is because she can't exist in the suffocatingly liberal spaces of tech, but we've got no evidence she was asked to leave her job over being outed this way. Rather, it seems like she's now one of Elon's many favored bluecheck warriors for his website. These people can easily earn 4-5 figures a month just by posting a lot (so long as they can curry Elon's favor) and between that and the potential of DOGE that Jennica appears to have read the winds of a career change. She spends an incredible amount of time lying or presenting banal truths as checkmates on Twitter.
Given the state of affairs outlined above, it's pretty clear that she's decided to lie on cue because it's very profitable for her to lie. We can see this because we've caught her lying here, and as this particular drama was going on she was weaving a bizarre narrative where she was denied a glamorous life in the counterfactual world where no one knew her politics:
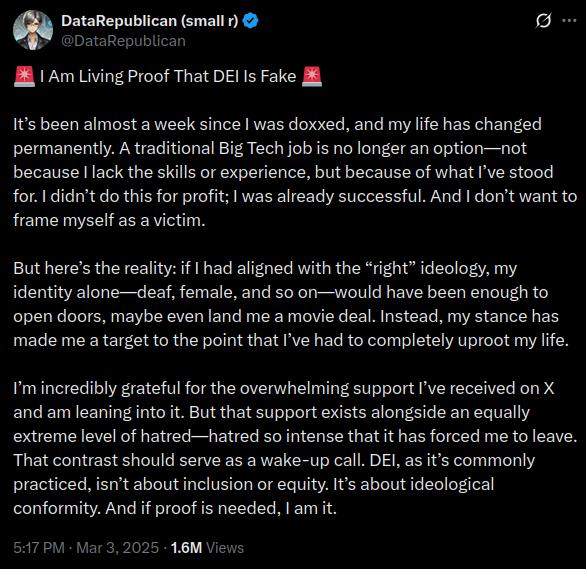
Pause for a moment. The post is audaciously contradictory:
As a fellow software engineer with a very similar stint as Director and some time in fintech, I want to point out that the idea being deaf and female would get her a movie deal is ridiculous. There are tons of women in the space, and some are also deaf. They neither have nor want movie deals. Jennica has all the marks of someone who has been leading a solid career with good growth.. Maybe DEI efforts from her employers made that more plausible, maybe not. But she's one of thousands of such people! DEI even on her terms seeks to make her less special, not more so.
Similarly, the idea that Republican politics gets you nuked out of industry is just silly. There are tons of republicans in big tech companies. Facebook is famously friendly to that attitude and has never been more focused on anti-DEI initiatives. Google is extremely agnostic on the subjectThe only high profile case here, of James Damore, was the story of a man who went out of his way to call every female coworker he had unworthy, including a woman in his reporting chain. He also seems to have violated his NDA in that episode as well., and my interactions with Snap were that they were extremely mercenary about that sort of thing. So long as everyone can shut the hell up and work with their peers to make value for the company, they do not give a crap. Jennica knows as well as I do that corporate DEI is about recruiting outreach, not about quotas.
What she's doing here is pointing out that she's a celebrity now that she's NOT in tech. She gets appearances on national television shows, attention from the richest man on earth (child pending? Who can say in 2025!), etc etc. Most of her work now is strange stuff like this. Paid content (via the oh-so-subtle mechanism of bluecheck dividends) to do character assassinations based on public data that then lead to broad pronouncements and policy. These pronouncements are often hedged by strange and hard-to-replicate stories, and promises of future followup work that never materialize.
And that's her place in all this. Her job is to craft arguments that are hard for lay people to refute. They don't have to be correct or relevant, they need to exist in a place the Right Wing can gesture to, to abstract the conversation away from the monstrous cruelty and incompetence they support and towards the irrelevant realm of "which team's expert is more credible in the eyes of God." This phenomenon has been well documented by Innuendo Studios. The goal is to give reactionaries a way to talk about everything but the values they're promoting.
Ultimately, the refutation you've read today is futile if the goal is to stop the DataRepublican grift. Jennica will never recant this absurd story because she doesn't have to. Her audience won't hold her accountable and her credibility is already permanently cemented by a LinkedIn that exists and a willingness to cooperate even to the detriment of her and her peers. The irony of her talking about her deafness, gender, sex and politics far more now in order to gain status in Elon's disinformation economy is probably lost on her. In some sense, her complaint is that her conjured notion of "DEI" didn't do more for her than the disinformation sphere can. And in that sense, she's not wrong. We've seen even peripheral people on Twitter catch Elon's eye and then see $30k USD monthly payment suddenly start to materialize, and it's unlikely she made more than a third of that at her peak in tech.
But maybe there's value to you and I, dear reader, as people united in a fascination with the tools we have to infer and measure the truth of the world around us. For us, at least, we can look and be confident that there isn't some grand conspiracy. Jennica Pounds is just a paid liar, turning up every day in the consent factorySee Manufacturing Consent by Herman & Chomsky to launder ideas for Republican influencers. She has no special access, no special data, and she's flagrantly lying. Maybe we can use her lies as a way to discover which parts of the truth the Right Wing is eager to obscure.
Our only upside, I suppose, is that debunking this claim was easy. We learned that the data she's using is accessible and small. We learned that for whatever reason, Elon's star data scientist is happy to make herself look ridiculous rather than admit she was wrong. That's a point of leverage we have: she doesn't understand her credibility might matter. And we learned that DuckDB turns this sort of analysis into something trivial.